
[ad_1]
Definition
- VisText
-
VisText is a benchmark dataset of over 12,441 charts and semantically wealthy captions! Within the VisText dataset, every chart is represented as its rasterized picture, scene graph specification, and underlying datatable. Every chart is paired with an artificial L1 caption that describes the chart’s elemental and ecoded properties and a human-generated L2/L3 caption that describes tendencies and statistics in regards to the chart.
Essential Digest
“VisText: A Benchmark for Semantically Wealthy Chart Captioning” – Massachusetts Institute of Expertise.
Chart captions that designate complicated tendencies and patterns are essential for enhancing a reader’s capability to understand and retain the information being offered. And for folks with visible disabilities, the data in a caption typically offers their solely technique of understanding the chart.
1 – Researchers Educate Synthetic Intelligence (AI) to Write Accessible Chart Captions
Writing efficient, detailed captions is a labor-intensive course of. Whereas autocaptioning methods can alleviate this burden, they typically battle to explain cognitive options that present extra context.
To assist folks creator high-quality chart captions, MIT researchers have developed a dataset to enhance computerized captioning techniques. Utilizing this device, researchers may educate a machine-learning mannequin to range the extent of complexity and kind of content material included in a chart caption primarily based on the wants of customers.
The MIT researchers discovered that machine-learning fashions skilled for autocaptioning with their dataset constantly generated captions that have been exact, semantically wealthy, and described knowledge tendencies and complicated patterns. Quantitative and qualitative analyses revealed that their fashions captioned charts extra successfully than different autocaptioning techniques.
The crew’s objective is to supply the dataset, known as VisText, as a device researchers can use as they work on the thorny downside of chart autocaptioning. These computerized techniques may assist present captions for uncaptioned on-line charts and enhance accessibility for folks with visible disabilities, says co-lead creator Angie Boggust, a graduate pupil in electrical engineering and laptop science at MIT and member of the Visualization Group within the Laptop Science and Synthetic Intelligence Laboratory (CSAIL).
“We have tried to embed loads of human values into our dataset in order that once we and different researchers are constructing computerized chart-captioning techniques, we do not find yourself with fashions that are not what folks need or want,” she says.
Boggust is joined on the paper by co-lead creator and fellow graduate pupil Benny J. Tang and senior creator Arvind Satyanarayan, affiliate professor of laptop science at MIT who leads the Visualization Group in CSAIL. The analysis can be offered on the Annual Assembly of the Affiliation for Computational Linguistics.
Human Centered Evaluation
The researchers have been impressed to develop VisText from prior work within the Visualization Group that explored what makes chart caption. In that examine, researchers discovered that sighted customers and blind or low-vision customers had totally different preferences for the complexity of semantic content material in a caption.
The group needed to convey that human-centered evaluation into autocaptioning analysis. To do this, they developed VisText, a dataset of charts and related captions that might be used to coach machine-learning fashions to generate correct, semantically wealthy, customizable captions.
Creating efficient autocaptioning techniques is not any simple activity. Present machine-learning strategies typically attempt to caption charts the best way they’d a picture, however folks and fashions interpret pure pictures in a different way from how we learn charts. Different methods skip the visible content material totally and caption a chart utilizing its underlying knowledge desk. Nonetheless, such knowledge tables are sometimes not out there after charts are revealed.
Given the shortfalls of utilizing pictures and knowledge tables, VisText additionally represents charts as scene graphs. Scene graphs, which will be extracted from a chart picture, include all of the chart knowledge but in addition embody extra picture context.
“A scene graph is like the perfect of each worlds – it comprises virtually all the data current in a picture whereas being simpler to extract from pictures than knowledge tables. As it is also textual content, we are able to leverage advances in trendy massive language fashions for captioning,” Tang explains.
They compiled a dataset that comprises greater than 12,000 charts – every represented as a knowledge desk, picture, and scene graph – in addition to related captions. Every chart has two separate captions: a low-level caption that describes the chart’s development (like its axis ranges) and a higher-level caption that describes statistics, relationships within the knowledge, and complicated tendencies.
The researchers generated low-level captions utilizing an automatic system and crowdsourced higher-level captions from human employees.
“Our captions have been knowledgeable by two key items of prior analysis: current pointers on accessible descriptions of visible media and a conceptual mannequin from our group for categorizing semantic content material. This ensured that our captions featured essential low-level chart components like axes, scales, and models for readers with visible disabilities, whereas retaining human variability in how captions will be written,” says Tang.
Translating Charts
As soon as they’d gathered chart pictures and captions, the researchers used VisText to coach 5 machine-learning fashions for autocaptioning. They needed to see how every illustration – picture, knowledge desk, and scene graph – and mixtures of the representations affected the standard of the caption.
“You may take into consideration a chart captioning mannequin like a mannequin for language translation. However as an alternative of claiming, translate this German textual content to English, we’re saying translate this ‘chart language’ to English,” Boggust says.
Their outcomes confirmed that fashions skilled with scene graphs carried out as properly or higher than these skilled utilizing knowledge tables. Since scene graphs are simpler to extract from current charts, the researchers argue that they is perhaps a extra helpful illustration.
In addition they skilled fashions with low-level and high-level captions individually. This system, generally known as semantic prefix tuning, enabled them to show the mannequin to range the complexity of the caption’s content material.
As well as, they carried out a qualitative examination of captions produced by their best-performing technique and categorized six forms of widespread errors. As an illustration, a directional error happens if a mannequin says a development is reducing when it’s truly growing.
This fine-grained, sturdy qualitative analysis was essential for understanding how the mannequin was making its errors. For instance, utilizing quantitative strategies, a directional error would possibly incur the identical penalty as a repetition error, the place the mannequin repeats the identical phrase or phrase. However a directional error might be extra deceptive to a consumer than a repetition error. The qualitative evaluation helped them perceive most of these subtleties, Boggust says.
These kinds of errors additionally expose limitations of present fashions and lift moral issues that researchers should contemplate as they work to develop autocaptioning techniques, she provides.
Generative machine-learning fashions, resembling people who energy ChatGPT, have been proven to hallucinate or give incorrect data that may be deceptive. Whereas there’s a clear profit to utilizing these fashions for autocaptioning current charts, it may result in the unfold of misinformation if charts are captioned incorrectly.
“Possibly which means that we do not simply caption every part in sight with AI. As an alternative, maybe we offer these autocaptioning techniques as authorship instruments for folks to edit. You will need to take into consideration these moral implications all through the analysis course of, not simply on the finish when we’ve a mannequin to deploy,” she says.
Boggust, Tang, and their colleagues need to proceed optimizing the fashions to cut back some widespread errors. In addition they need to broaden the VisText dataset to incorporate extra charts, and extra complicated charts, resembling these with stacked bars or a number of traces. And they might additionally like to realize insights into what these autocaptioning fashions are literally studying about chart knowledge.
This analysis was supported, partially, by a Google Analysis Scholar Award, the Nationwide Science Basis, the MLA@CSAIL Initiative, and the USA Air Drive Analysis Laboratory.
2 – Blind and Sighted Readers Have Sharply Completely different Takes on What Content material Is Most Helpful to Embody in a Chart Caption
By Adam Zewe, Massachusetts Institute of Expertise (October 12, 2021)
Within the early days of the COVID-19 pandemic, the Facilities for Illness Management and Prevention produced a easy chart for example how measures like masks carrying and social distancing may “flatten the curve” and cut back the height of infections.
Continued…
The chart was amplified by information websites and shared on social media platforms, nevertheless it typically lacked a corresponding textual content description to make it accessible for blind people who use a display reader to navigate the net, shutting out most of the 253 million folks worldwide who’ve visible disabilities.
This various textual content is commonly lacking from on-line charts, and even when it’s included, it’s continuously uninformative and even incorrect, in response to qualitative knowledge gathered by scientists at MIT.
These researchers carried out a examine with blind and sighted readers to find out which textual content is beneficial to incorporate in a chart description, which textual content isn’t, and why. Finally, they discovered that captions for blind readers ought to deal with the general tendencies and statistics within the chart, not its design components or higher-level insights.
In addition they created a conceptual mannequin that can be utilized to guage a chart description, whether or not the textual content was generated robotically by software program or manually by a human creator. Their work may assist journalists, teachers, and communicators create descriptions which are more practical for blind people and information researchers as they develop higher instruments to robotically generate captions.
“Ninety-nine-point-nine p.c of pictures on Twitter lack any sort of description-and that’s not hyperbole, that’s the precise statistic,” says Alan Lundgard, a graduate pupil within the Laptop Science and Synthetic Intelligence Laboratory (CSAIL) and lead creator of the paper. “Having folks manually creator these descriptions appears to be tough for quite a lot of causes. Maybe semiautonomous instruments may assist with that. However it’s essential to do that preliminary participatory design work to determine what’s the goal for these instruments, so we aren’t producing content material that’s both not helpful to its supposed viewers or, within the worst case, misguided.”
Lundgard wrote the paper with senior creator Arvind Satyanarayan, an assistant professor of laptop science who leads the Visualization Group in CSAIL. The analysis can be offered on the Institute of Electrical and Electronics Engineers Visualization Convention in October.
Evaluating Visualizations
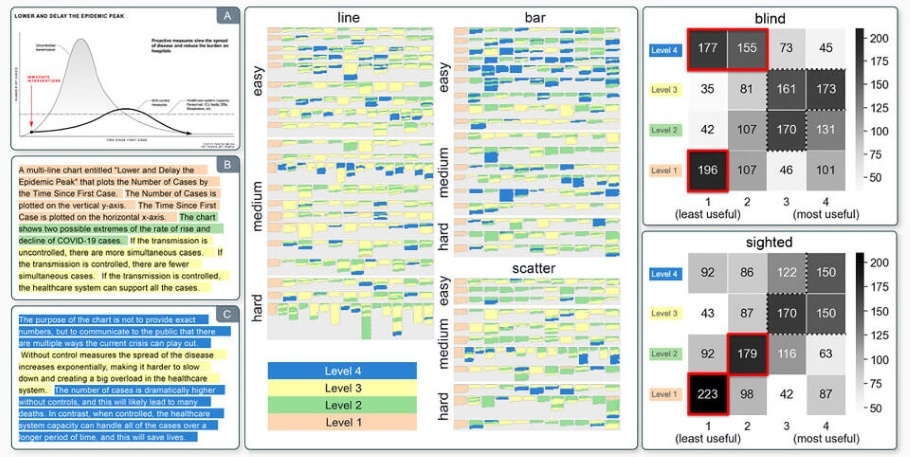
To develop the conceptual mannequin, the researchers deliberate to start by learning graphs featured by widespread on-line publications resembling FiveThirtyEight and NYTimes.com, however they ran right into a problem-those charts largely lacked any textual descriptions. So as an alternative, they collected descriptions for these charts from graduate college students in an MIT knowledge visualization class and thru an internet survey, then grouped the captions into 4 classes.
- Degree 1 descriptions deal with the weather of the chart, resembling its title, legend, and colours.
- Degree 2 descriptions describe statistical content material, just like the minimal, most, or correlations.
- Degree 3 descriptions cowl perceptual interpretations of the information, like complicated tendencies or clusters.
- Degree 4 descriptions embody subjective interpretations that transcend the information and draw on the creator’s information.
In a examine with blind and sighted readers, the researchers offered visualizations with descriptions at totally different ranges and requested members to fee how helpful they have been. Whereas each teams agreed that stage 1 content material by itself was not very useful, sighted readers gave stage 4 content material the very best marks whereas blind readers ranked that content material among the many least helpful.
Survey outcomes revealed {that a} majority of blind readers have been emphatic that descriptions mustn’t include an creator’s editorialization, however quite follow straight info in regards to the knowledge. However, most sighted readers most popular an outline that informed a narrative in regards to the knowledge.
“For me, a stunning discovering in regards to the lack of utility for the highest-level content material is that it ties very carefully to emotions about company and management as a disabled individual. In our analysis, blind readers particularly did not need the descriptions to inform them what to consider the information. They need the information to be accessible in a approach that enables them to interpret it for themselves, they usually need to have the company to try this interpretation,” Lundgard says.
A Extra Inclusive Future
This work may have implications as knowledge scientists proceed to develop and refine machine studying strategies for autogenerating captions and various textual content.
“We’re not in a position to do it but, however it’s not inconceivable to think about that sooner or later we might be capable to automate the creation of a few of this higher-level content material and construct fashions that concentrate on stage 2 or stage 3 in our framework. And now we all know what the analysis questions are. If we need to produce these automated captions, what ought to these captions say? We’re in a position to be a bit extra directed in our future analysis as a result of we’ve these 4 ranges,” Satyanarayan says.
Sooner or later, the four-level framework may additionally assist researchers develop machine studying fashions that may robotically recommend efficient visualizations as a part of the information evaluation course of, or fashions that may extract essentially the most helpful data from a chart.
This analysis may additionally inform future work in Satyanarayan’s group that seeks to make interactive visualizations extra accessible for blind readers who use a display reader to entry and interpret the data.
“The query of how to make sure that charts and graphs are accessible to display reader customers is each a socially essential fairness concern and a problem that may advance the state-of-the-art in AI,” says Meredith Ringel Morris, director and principal scientist of the Folks + AI Analysis crew at Google Analysis, who was not concerned with this examine. “By introducing a framework for conceptualizing pure language descriptions of knowledge graphics that’s grounded in end-user wants, this work helps be sure that future AI researchers will focus their efforts on issues aligned with end-users’ values.”
Morris provides:
“Wealthy natural-language descriptions of knowledge graphics is not going to solely broaden entry to important data for people who find themselves blind, however will even profit a a lot wider viewers as eyes-free interactions through sensible audio system, chatbots, and different AI-powered brokers turn into more and more commonplace.”
This quality-reviewed article regarding our Web site Accessibility part was chosen for publishing by the editors of Disabled World as a consequence of its seemingly curiosity to our incapacity neighborhood readers. Although the content material could have been edited for fashion, readability, or size, the article “VisText: Instructing AI to Write Higher Accessible Chart Captions” was initially written by Massachusetts Institute of Expertise, and revealed by Disabled-World.com on 2023/07/02. Must you require additional data or clarification, Massachusetts Institute of Expertise will be contacted at net.mit.edu. Disabled World makes no warranties or representations in connection therewith.
Share This Data To:
𝕏.com Fb Reddit
Web page Data, Citing and Disclaimer
Disabled World is an impartial incapacity neighborhood based in 2004 to supply incapacity information and knowledge to folks with disabilities, seniors, their household and/or carers. See our homepage for informative evaluations, unique tales and how-tos. You may join with us on social media resembling X.com and our Fb web page.
Permalink: <a href=”https://www.disabled-world.com/incapacity/accessibility/websitedesign/vistext.php”>VisText: Instructing AI to Write Higher Accessible Chart Captions</a>
Cite This Web page (APA): Massachusetts Institute of Expertise. (2023, July 2). VisText: Instructing AI to Write Higher Accessible Chart Captions. Disabled World. Retrieved November 17, 2023 from www.disabled-world.com/incapacity/accessibility/websitedesign/vistext.php
Disabled World offers common data solely. Supplies offered are by no means meant to substitute for certified skilled medical care. Any third occasion providing or promoting doesn’t represent an endorsement.
[ad_2]